Hugging Face 🤗 is darn slick. Your project is built into a docker image and then launched as needed. Github could learn a thing or two about showing status. There was some errors due to the fastai API changing to no longer needing you to wrap an image that you want to predict in a PILImage and another problem with adding example images, that I solved by just removing them.
The biggest change since I last took a course on Machine Learning is one of the key points of this course: the use of foundational models that you fine tune to get great results. In this lesson’s video we fine tune an image classifier to see if a picture has a bird in it.
While building my own model I attempted to get the classifier fine tuned to look at comic book covers and tell me what publisher it was from. I thought with the publishers mark on 100 issues from Marvel, DC, Dark Horse, and Image the classifier would be able to tell. The best I was able to do was about 30% error rate, a far cry from the 0% in the example models. I tried a few different ideas of how to improve:
train with larger images. The notebook used in the video makes the training go faster by reducing the size of the image. As I write this I wonder if it is even possible to use larger images in a model that might have been trained on a fixed size.
create a smaller image by getting the 4 corners of the cover into one image.
clean the data so that all the covers in the dataset had a publisher mark on them.
sample cover from X-Men Red #2 with only the corners
Nothing moved the needle. I’m hoping something I learn later in the course will give me the insight I need to do better.
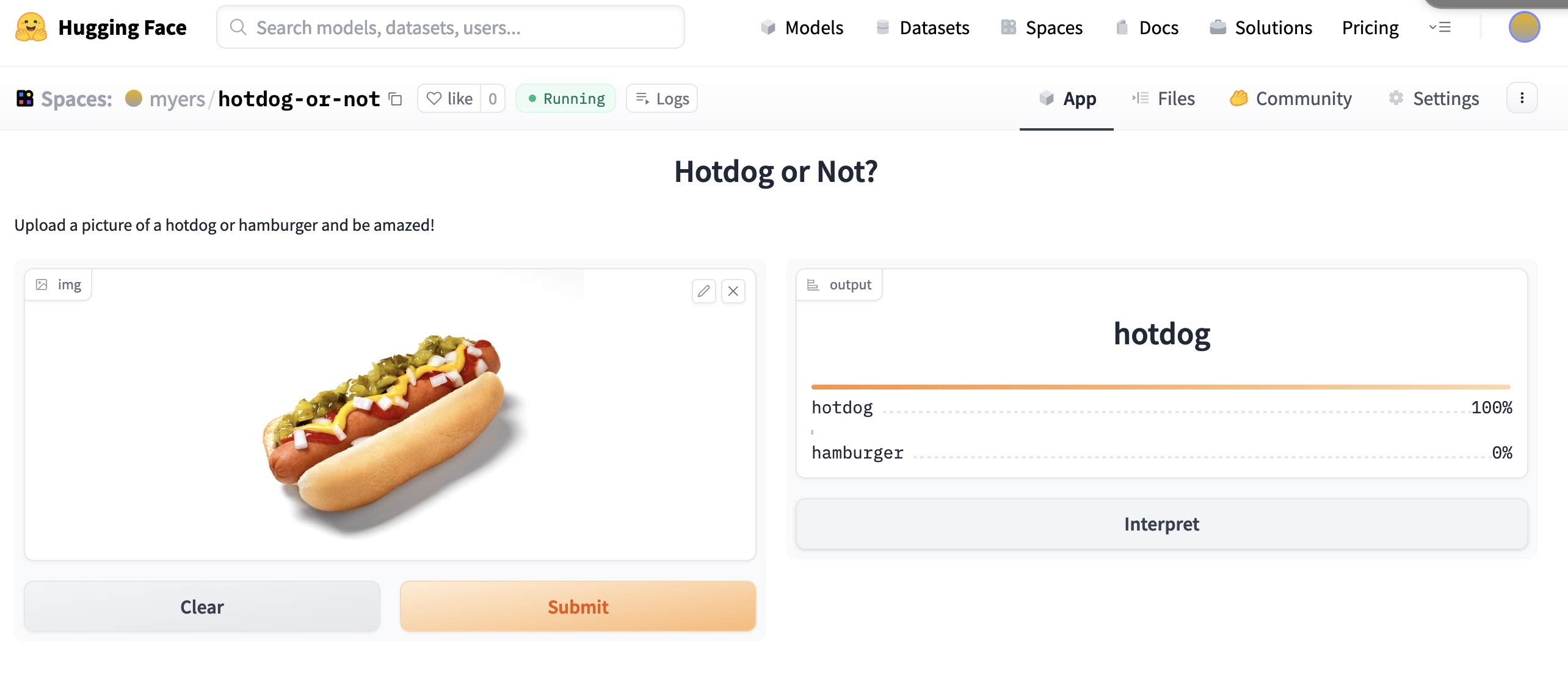
I took a second attempt with a simpler project. Of course I remembered that Silicon Valley episode with the hot dog detector, and make a hot dog vs hamburger classifier. It works great. The next lesson covers getting a model like that into production, so hang tight.
Practical work is the goal. Don’t fool yourself into thinking you know what is taught by just watching the videos or reading the book. Watch the video, watch it again but with the tools at hand, pausing to try stuff out, do a project using what you learned. The title of this blog is me trying to remind myself of this concept.
I have my own ML workstation setup with a GPU. I used poetry to set it up. This was a pain due to lack of attention to repeatability in Jupyter Notebooks. It would be very useful if they had a “lock” feature that records all python packages in the environment they are run it and their exact version. Below is what it looks like after finishing Lesson 1 (the next video).
Be tenacious. Finish a project.
One message that’s very close to my heart is not keep on getting ready to do a project, like stopping to learn linear algebra (and then remembering how I never learned all the math terms, and therefore want to go back even deeper) in order to do well on this course. Try to do a complete project, then on the next project go deeper, dig in deeper when the code needs it.
Show your work to the world. Blog not to be a breaking news source, but blog for the audience of yourself 6 months ago.
The Economist covers It doesn’t take much to make machine-learning algorithms go awry. Will we see a core of knowledge built that considered “The Truth”, and then all other input data is evaluated on how likely that’s true based on the givens? LLMs judging what is fed to their younger siblings?
 001-000.jpg)